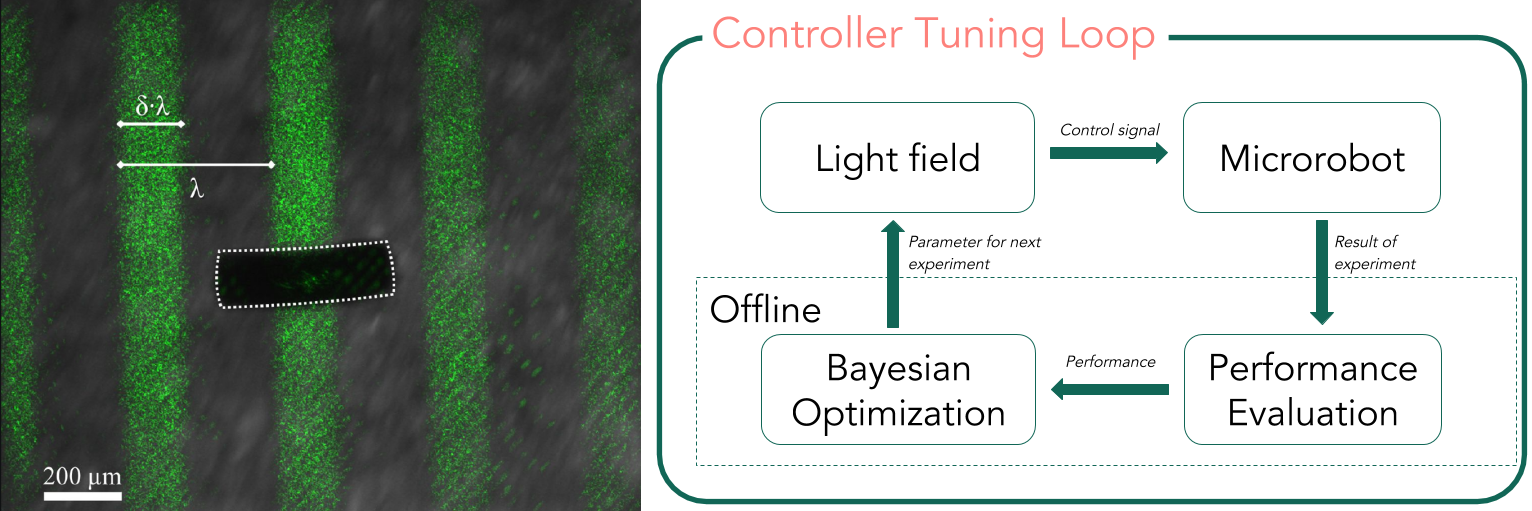
Left: A photo of the soft microrobot (black, white dotted outline) powered and controlled by a light field. When the light pattern moves to the left, the microrobot moves to the right. The light forms a rectangular wave where the wave length and the on-off ratio can be adjusted according to the microrobot and the desired traveling speed. Right: Learning controller parameters from data [ ]. In each iteration, the controller generates a different dynamic light field (symbolized by the green stripes). The microrobot's position during the experiment is tracked and the result of the experiment is added to the data set. To determine what experiment to do next, a model of the controller performance is used and optimized via Bayesian Optimization. In the next iteration, a new set of parameters will be evaluated.
Soft robots are a class of robots constructed from highly deformable materials, inspired by the bodies of living organisms. In [ ], Palagi et al. have introduced soft microrobots based on stimuli-responsive polymers. Projecting a light field onto the surface heats part of the microrobot's body therefore creating a local deformation. With the correct light fields, the microrobots are able to produce periodic deformations that can be used to create locomotion. By changing the light field, the corresponding deformation of the microrobot changes and thereby creates a different kind of movement, which we call locomotion patterns [ ]. However, the deformations and the resulting locomotion behavior are hard to model. Therefore, designing a suitable controller for the desired locomotion is challenging. In this project, we circumvent the need for exact physics-based models by employing machine learning. We use data gathered during experiments to automatically learn a suitable controller. This is one of the first works that uses data driven methods on robotic agents at the micrometer scale.
In [ ], we propose learning locomotion patterns using Gaussian Processes and Bayesian Optimization (see figure). The resulting learning scheme evaluates a given controller based on experimental data and uses a Gaussian Process to model the controller performance. In the next step, a new set of controller parameter is chosen automatically and tested in the next experiment. We showed that the proposed learning scheme is able to improve the locomotion performance in a data-efficient way. A semi-synthetic benchmark (obtained made from previously collected data) is used to compare different settings of the learning scheme. The best parameters found by the benchmark were validated experimentally, and the locomotion speed improved by more than a factor of two (115%) with only 20 experiments.
Future work aims to extend the learning scheme such that the controller can adapt to changing environments by learning spatio-temporal correlations, as well as a systematic way of excluding old and unimportant data from the learning process.